
在 AI 领域,人们常常低估了存储在模型推理阶段的重要性。然而,数据基础设施实际上对模型的加载时间、GPU 使用效率、延迟和整体性能有着直接的影响。了解 WEKA Data Platform 如何显著提升推理操作的速度和效率,为未来发展奠定坚实基础。
大型语言模型(LLM)的推理阶段
大型语言模型(LLM)是当今许多 AI 应用的基础。利用深度学习(Deep Learning)和神经网络(Neural Networks),这些复杂而精密的 AI 模型能够处理和生成基于语言的任务,包括文本生成、翻译、摘要和问答等。
部署 LLM 的第一步是对其进行训练,这需要庞大的文本数据集。训练完成后,模型进入推理阶段。推理阶段是使用训练好的模型,根据新输入数据进行预测或生成输出的过程。通过推理,模型将其知识应用于实际场景,如图像识别、语言翻译和推荐系统等实时应用。经过训练的模型可以将学到的模式和关系应用到新的、未见过的数据中,从而产生结果。这是部署 AI 系统的关键步骤,使其能够在现实世界中执行各种任务。
通常,完整的模型文件大小在数十至数百 GB 之间。每个模型都要经过训练,以满足特定操作或用户需求,例如数据嵌入或理解和回答文本内容。这一过程通常在使用 GPU 的服务器或云实例(云端计算资源)上进行(市面上还有其他加速器,如 IPU、TPU、WSE 甚至 CPU)。一些知名的大规模推理模型包括 OpenAI 的 ChatGPT、Cohere 的 Command-R、NVIDIA 的 Megatron 和 Meta 的 Llama。许多其他模型则是自行训练或从 Hugging Face 等模型库中获取的开源模型,用于发布、比较和共享。
WEKA在提升 AI 训练阶段的性能和扩展性方面经验丰富。如今,随着越来越多的关注点转向推理阶段,WEKA 也在应对这一阶段的关键挑战。
推理阶段的挑战
在推理阶段,模型通常运行在 GPU 内存中,很多人误以为存储不重要,但实际情况是,存储对推理的速度和效率有很大影响。由于这个误解,导致许多昂贵的 GPU 实例(资源)被浪费。在推理过程中,系统需要快速处理突发的 API 请求,同时保证用户得到快速响应。这意味着企业常常为那些利用率低的 GPU 资源付费。如果能更快创建新的推理任务并将模型加载到 GPU 内存中,系统就能更高效地处理更多的任务,从而提高 GPU 的使用效率,节省成本。
WEKA 案例——LinguaModel Labs
让我们来看看一位 WEKA 客户在推理过程中遇到的存储相关挑战,以及 WEKA 是如何帮助他们加快推理速度、改善服务质量、降低成本并简化环境。
WEKA 与一家知名的 LLM 供应商合作,这家公司在云端运营大规模的 LLM,以下简称为 “LinguaModel Labs”。
LinguaModel Labs 在推理效率和性能方面遇到了挑战。他们的推理系统包含多个 GPU 实例,负责将模型加载到 GPU 内存中并运行。这个推理系统的设计目的是能够快速加载新模型,并根据需求动态扩展,以应对来自 API 请求的各种突发推理任务。
LinguaModel Labs 面临的挑战
模型加载:把相关模型迅速加载到 GPU 内存中,并根据需要在不同模型之间快速切换。
扩展 GPU 实例:当负载增加时,要能够迅速增加更多的 GPU 计算资源。
最大化 GPU 利用率:充分利用现有的 GPU 实例,以提高其价值和效率。
WEKA 如何帮助优化推理过程

使用 WEKA 后,LinguaModel Labs 的推理能力得到了显著提升。
1.更快的模型加载时间
存储系统升级:从 S3 存储迁移到高性能文件系统,显著提升了模型加载速度。
动态启动优化:动态启动 GPU 推理实例的时间减少了一半,从而显著缩短了模型加载到 GPU 内存的时间。
加载时间缩短:例如,13GB 的模型文件加载时间从 265 秒减少到 195 秒,100 GB+的大型模型的加载时间也与之前的小模型相当。
2.增强云环境互操作性
快照和复制功能:WEKA 的快照和复制功能使 LinguaModel Labs 能够在不同的云平台之间无缝共享模型,提高了灵活性和效率。
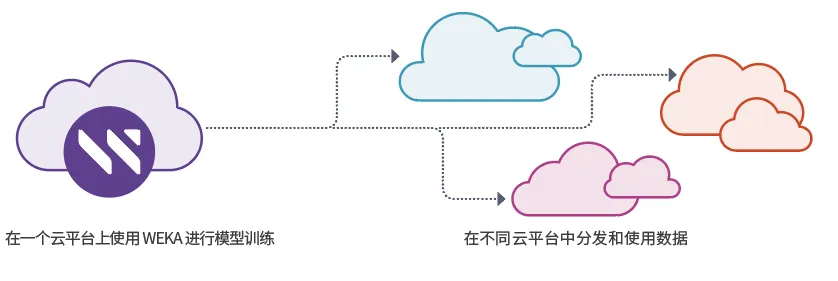
3.面相未来的 GPU 直连存储 (GDS)
使用 GPU 直连存储(GPU Direct Storage)进一步缩短了模型加载时间,并为未来的 GPU 内存扩展提供支持。
以 80 GB/s 的速度在云中将数据快速加载到 GPU 内存
1 秒钟使 GPU 内存饱和
使用 GDS 技术实现 190GB/s 的数据加载速度
WEKA 在推理环境中的额外优势

除了提升性能,WEKA 数据平台还提供其他一些重要优势。
1.高效下载推理工件
WEKA 能够快速下载 LLM 推理工件(如文本、音频、视频),释放 GPU 和 CPU 内存,从而最大化 GPU 的利用率和效益。
推理工件(inferencing artifacts)是指机器学习模型在执行推理任务时产生的所有数据和结果。
2.快速加载和卸载 GPU 内存
WEKA 能在一秒钟内完成 GPU 内存的加载和卸载。这意味着 GPU 可以迅速保存当前的会话、状态和数据到稳定存储中。然后腾出空间给其他推理任务。而之前的会话可以在需要时被加载到其他 GPU 上,从上次的进度继续推理。
3.提高嵌入频率
WEKA 通过检索增强技术,使得模型能够更频繁地进行数据嵌入。这种方法减少了模型的“幻觉”现象,并确保模型能提供最新、最准确的答案。借助 WEKA, 组织可以更频繁地更新嵌入数据,从而利用最新、最准确的信息源,获得更可靠的查询结果。
“嵌入频率”指的是模型将新数据嵌入或整合进现有模型中的频率。这里的“嵌入”是指将外部数据(如文本、图像、音频等)转换成模型可以理解和处理的格式。
“模型幻觉”(model hallucinations)是指机器学习模型生成的虚假、不准确或不相关的信息。这种现象发生时,模型可能会“编造”一些看似合理但实际上并不正确的回答或内容。这通常是因为模型在训练过程中接触的数据有限或不完全,或者模型对上下文的理解不够准确。
WEKA 数据平台通过优化存储和计算资源管理,显著提升了 LinguaModel Labs 的推理效率,使其更快、更高效,并具备了未来扩展的能力。这一方案不仅解决了当前的技术挑战,还为未来在 AI 和机器学习领域的持续创新奠定了坚实基础。
对于希望提升推理效率并优化成本的企业,WEKA 数据平台无疑是理想选择。

联系瑞技
了解更多关于 WEKA如何加速 LLM 推理,为 AI 和 ML发展奠定坚实基础的信息,请联系 WEKA 中国地区合作伙伴——瑞技科技。
400-8866-490 | sales.cn@bytebt.com




