
1984年,孙正义因宣称“网络即计算机”而闻名。四十年后,随着人工智能的到来,我们再一次看到这一周期的到来。AI 训练模型的集体性质依赖于无损、高可用性的网络,以便无缝地将集群中的每个 GPU 相互连接,并实现峰值性能。网络还将训练过的 AI 模型与数据中心的最终用户和其他系统(如存储系统)连接起来,从而使系统成为超越各部分总和的存在。因此,数据中心正在演变为新的 AI 中心,而网络则成为 AI 管理的中心。
AI 趋势
为了理解这一点,让我们首先关注 AI 数据集的爆炸式增长。随着 AI 训练中大型语言模型(LLMs)规模的扩大,数据并行化变得不可避免。训练这些更大规模模型所需的 GPU 数量无法跟上庞大的参数数量和数据集大小。无论是数据、模型还是管道,AI 并行化的有效性都取决于将 GPU 相互连接的网络。GPU 必须交换和计算全局梯度以调整模型的权重。为此,AI 难题的各个不同组成部分必须作为单一的 AI 中心协同工作:GPU、网卡(NICs)、光学/线缆等互连配件、存储系统,以及最重要的中心网络。
信息孤岛
在当今基于 AI 的数据中心中,性能不理想的原因有很多。首先,AI 网络需要一致的端到端服务质量以保证无损传输。这意味着服务器中的网卡以及网络平台必须拥有统一的标记/映射、精确的控制和拥塞通知(包括使用数据中心量化拥塞控制(DCQCN)的优先流控制(PFC)和显式拥塞通知(ECN))以及适当的缓冲区利用率阈值,以使每个组件都能及时响应网络事件(如拥塞),确保发送方能够精确控制流量速率,避免丢包。然而,目前网卡和网络设备是分开配置的,在大型 AI 网络中,任何配置不匹配都极难调试。
性能不佳的一个常见原因是组件故障。服务器、GPU、网卡、收发器、电缆、交换机和路由器都可能出现故障,导致重传(go-back)或更糟糕的结果——可能使整个作业停滞,从而导致巨大的性能损失。随着集群规模的扩大,组件发生故障的可能性变得越来越大。传统上,GPU 供应商的集体通信库(CCL)会尝试使用定位技术来发现底层网络拓扑,但发现的拓扑与实际拓扑之间的差异可能会严重影响 AI 训练的作业完成时间。
AI 网络的另一个问题是,大多数运营商都有单独的团队来设计和管理不同的计算和网络基础设施。这涉及使用不同的编排系统进行配置、验证、监控和升级。缺乏单点控制和可见性使得识别和定位性能问题变得极其困难。随着 AI 集群规模的扩大,这些问题会变得更加严重。
不难看出,这些孤岛问题是如何不断加剧问题的严重性的。计算和网络之间的分割会导致将这两项技术结合起来以最大化性能的操作充满挑战,同时延误诊断和解决性能下降或宕机等问题。网络本身也可以分为基于以太网的数据中心网络和 InfiniBand 高性能计算(HPC)集群孤岛网络。这反过来又可能造成孤岛间数据传输的挑战,迫使组织使用笨拙的网关,并造成计算和存储到最终用户的连接障碍。只关注某一技术(如计算)而忽视整体解决方案的其他方面,会忽视技术之间相互依赖和相互连接的本质,如下图所示。
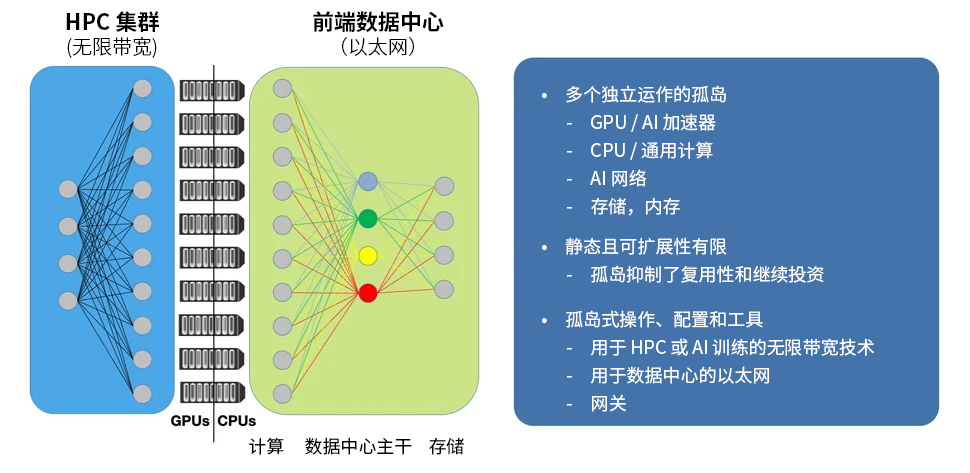
新 AI 中心的崛起
新的 AI 中心认识和接受了这一现代、相互依存的生态系统的整体性。整个系统共同提升以达到最佳性能,而不是像之前的网络孤岛那样孤立无援。GPU 需要一个优化和无损的网络,以便在最短的时间内完成 AI 训练,然后这些训练好的 AI 模型需要连接到 AI 推理集群,以便最终用户能够查询模型。计算节点,包括 GPU / AI 加速器和 CPU / 通用计算,也需要与存储系统以及现有数据中心中的其他 IT 系统进行通信和连接。没有任何部分是孤立工作的,网络就像连接组织一样,激发了所有交互点,就像神经系统为人类神经元提供通路一样。
每个部分的价值在于整个系统作为一个整体相互连接所产生的集体结果,而不是单个部分孤立工作的成果。对于人类来说,价值来自于神经系统所赋予的思想和行动,而不仅仅是神经元本身。同样,AI 中心的价值在于最终用户通过 AI 解决问题所消耗的输出,这些输出是由训练集群与推理集群、存储系统和其他 IT 系统相连接,并集成到一个无损网络中作为中枢神经系统而实现的。AI 中心通过消除孤岛,实现完美的性能调优、故障排除和运营而大放异彩,其中中央网络在创建和驱动这一互联系统中发挥着核心作用。
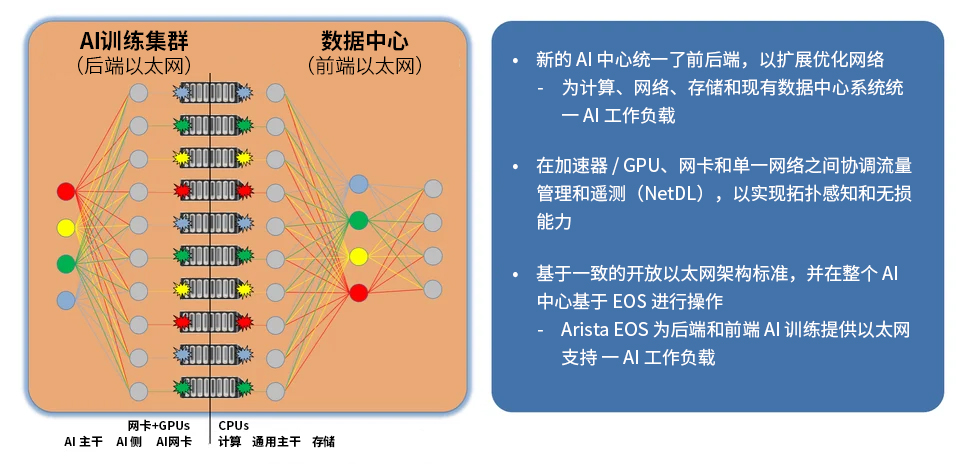
Arista EOS 为 AI 中心提供支持
EOS 是 Arista 的顶级操作系统,它支持全球最大的扩展型 AI 网络,将生态系统的所有部分整合在一起,以创建新的 AI 中心。如果说网络是 AI 中心的神经系统,那么 EOS 就是驱动这个神经系统的大脑。
Arista 的一项新创新被集成到 EOS 中,通过更紧密地将网络与连接的主机作为一个整体系统联系起来,进一步扩展了 AI 中心的互联概念。EOS 将网络范围内的控制、遥测和无损 QoS(服务质量)特性从网络交换机扩展到直连在服务器 / GPU 上的网卡上的远程 EOS 代理。部署在 AI 网卡 / 服务器上的远程代理将交换机转变为 AI 网络的中心,以便对 AI 主机和 GPU 进行配置、监控和故障调试。这将产生一个单一且统一的控制和可视化点。利用远程代理,可以确保包括端到端流量调优在内的配置的一致性。Arista EOS 实现了 AI 中心的通信,以便即时跟踪和报告主机和网络行为。这样就可以在网络中运行的 EOS 与主机上的远程代理之间的通信中隔离故障。这意味着 EOS 可以直接报告网络拓扑,集中进行拓扑发现,并利用熟悉的 Arista EOS 配置和管理结构来跨所有 Arista Etherlink™ 平台和合作伙伴进行操作。
丰富的合作生态系统:AMD、Broadcom、Intel 和 NVIDIA
Arista AI 中心的目标是以最低的作业时间来构建强大、超大规模的 AI 网络。它正在将网络交换机、网卡、收发器、电缆、GPU 和服务器等整个生态系统整合到新的 AI 中心中,并作为单一组件进行配置、管理和监控。这种方式降低了总成本,并提高了计算或网络的生产力。AI 中心的愿景是实现 AI 网络与主机之间开放、连贯的互操作性和可管理性的第一步。欢迎来到 AI 中心的新世界!

联系瑞技
Arista 坚持 EOS 开放标准的承诺,利用 OpenConfig 来支持新时代的 AI 中心。欢迎联系 Arista 在华正规授权代理商——瑞技科技,一起探讨 AI 中心的奥妙吧。
400-8866-490 | sales.cn@bytebt.com




